


SolidityBench de IQ ha sido lanzado como la principal clasificación para juzgar LLMs en la era del código Solidity. Disponible en Hugging Face, introduce dos pruebas modernas, NaïveJudge y HumanEval para Solidity, diseñadas para evaluar y clasificar la eficacia de los modelos de IA en la generación de código de contratos inteligentes.
Desarrollado por BrainDAO de IQ como parte de su próxima suite de códigos IQ, SolidityBench sirve para refinar sus propios LLMs EVMind y compararlos con modelos generalistas y creados por la comunidad. IQ Code tiene como objetivo proporcionar modelos de IA adaptados para la generación y auditoría de código de contratos inteligentes, abordando la creciente necesidad de aplicaciones blockchain seguras y eficientes.
Según IQ, NaïveJudge ofrece un enfoque único al asignar a los LLMs la tarea de implementar contratos inteligentes basados en especificaciones detalladas derivadas de contratos auditados de OpenZeppelin. Estos contratos proporcionan un estándar de oro para la corrección y eficiencia. El código generado se evalúa frente a una implementación de referencia utilizando criterios como completitud funcional, adherencia a las mejores prácticas de Solidity y estándares de seguridad, y eficiencia de optimización.
El proceso de evaluación utiliza LLMs avanzados, incluidas diferentes versiones del GPT-4 de OpenAI y Claude 3.5 Sonnet como revisores de código neutrales. Evalúan el código en base a criterios rigurosos, incluyendo la implementación de todas las funcionalidades clave, manejo de casos límite, gestión de errores, uso adecuado de la sintaxis y estructura general y mantenibilidad del código.
También se evalúan aspectos de optimización como la eficiencia de gas y la gestión de almacenamiento. Las puntuaciones van de 0 a 100, proporcionando una evaluación integral en funcionalidad, seguridad y eficiencia, reflejando las complejidades del desarrollo profesional de contratos inteligentes.
¿Qué modelos de IA son los mejores para el desarrollo de contratos inteligentes en Solidity?
Los resultados de la prueba mostraron que el modelo GPT-4o de OpenAI logró la mayor puntuación total de 80.05, con una puntuación de NaïveJudge de 72.18 y tasas de aprobación de HumanEval para Solidity del 80% en cross@1 y del 92% en cross@3.
Curiosamente, modelos de razonamiento más nuevos como el o1-preview y o1-mini de OpenAI fueron superados en el primer puesto, con puntuaciones de 77.61 y 75.08, respectivamente. Modelos de Anthropic y XAI, junto con Claude 3.5 Sonnet y grok-2, demostraron un rendimiento competitivo con puntuaciones totales rondando el 74. El Llama-3.1-Nemotron-70B de Nvidia obtuvo la puntuación más baja en el top 10 con 52.54.
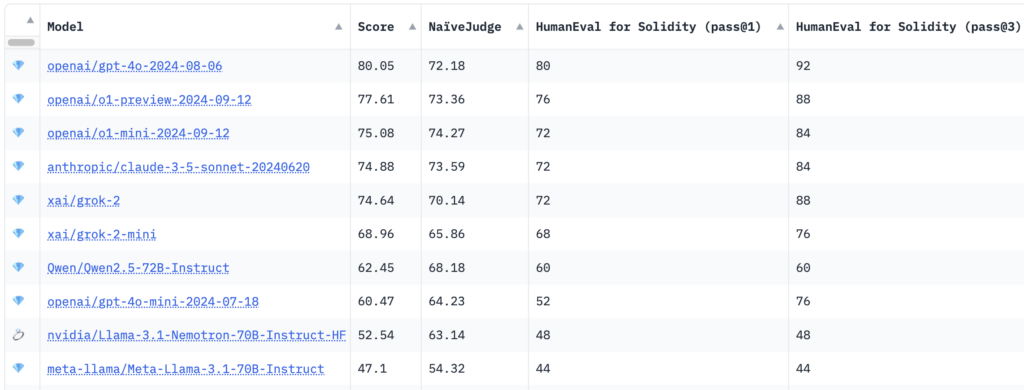
Según IQ, HumanEval for Solidity adapta el benchmark original HumanEval de OpenAI de Python a Solidity, abarcando 25 tareas de diferentes dificultades. Cada tarea incluye pruebas correspondientes compatibles con Hardhat, un entorno de desarrollo Ethereum popular, facilitando la compilación y prueba precisa del código generado. Las métricas de evaluación, cross@1 y cross@3, miden el éxito del modelo en intentos iniciales y en varios intentos, ofreciendo información sobre la precisión y capacidades de resolución de problemas.
Objetivos de usar modelos de IA en el desarrollo de contratos inteligentes
Al introducir estos benchmarks, SolidityBench busca avanzar en el desarrollo asistido por IA de contratos inteligentes. Fomenta la creación de modelos de IA más sofisticados y confiables, al mismo tiempo que proporciona a los desarrolladores e investigadores información valiosa sobre las capacidades actuales y limitaciones de la IA en el desarrollo de Solidity.
El kit de pruebas tiene como objetivo mejorar los LLMs EVMind de IQ Code y establecer nuevos estándares para el desarrollo de contratos inteligentes asistido por IA en el ecosistema blockchain. La iniciativa espera abordar una necesidad crítica en la industria, donde la demanda de contratos inteligentes seguros y eficientes sigue creciendo.
Se invita a desarrolladores, investigadores y entusiastas de la IA a explorar y contribuir a SolidityBench, que tiene como objetivo impulsar el refinamiento continuo de modelos de IA, promover las mejores prácticas y avanzar en las aplicaciones descentralizadas.
Visita el ranking de SolidityBench en Hugging Face para obtener más información y comenzar a evaluar los modelos de generación de Solidity.
Mencionado en este artículo
